 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Human-AI Triadic Programming: Uncovering the Role of AI Agent and the Value of Human Partner in Collaborative Learning
Jan 17, 2026As AI assistance becomes embedded in programming practice, researchers have increasingly examined how these systems help learners generate code and work more efficiently. However, these studies often position AI as a replacement for human collaboration and overlook the social and learning-oriented aspects that emerge in collaborative programming. Our work introduces human-human-AI (HHAI) triadic programming, where an AI agent serves as an additional collaborator rather than a substitute for a human partner. Through a within-subjects study with 20 participants, we show that triadic collaboration enhances collaborative learning and social presence compared to the dyadic human-AI (HAI) baseline. In the triadic HHAI conditions, participants relied significantly less on AI-generated code in their work. This effect was strongest in the HHAI-shared condition, where participants had an increased sense of responsibility to understand AI suggestions before applying them. These findings demonstrate how triadic settings activate socially shared regulation of learning by making AI use visible and accountable to a human peer, suggesting that AI systems that augment rather than automate peer collaboration can better preserve the learning processes that collaborative programming relies on.
FixEval: Execution-based Evaluation of Program Fixes for Competitive Programming Problems
Jun 15, 2022
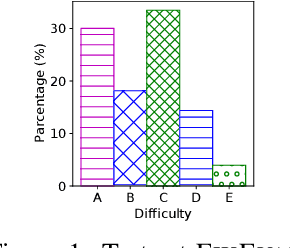
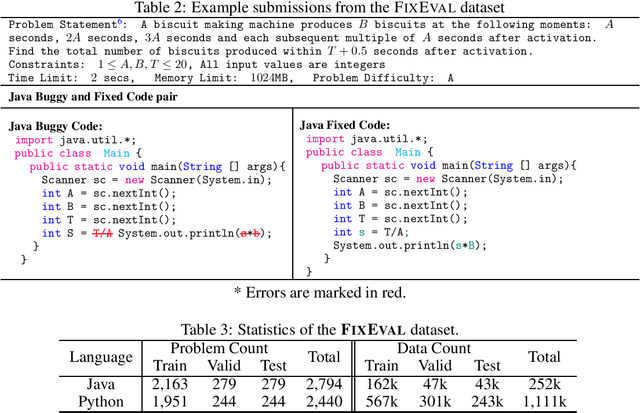
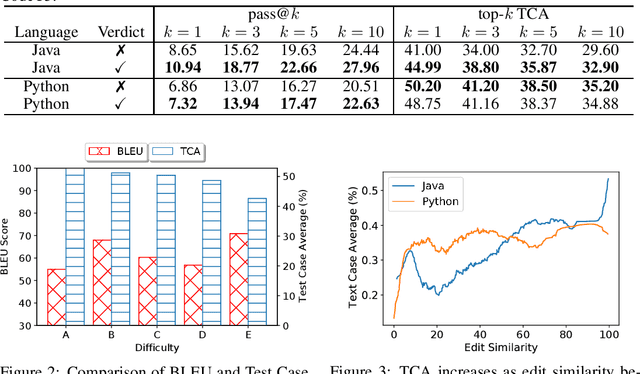
Source code repositories consist of large codebases, often containing error-prone programs. The increasing complexity of software has led to a drastic rise in time and costs for identifying and fixing these defects. Various methods exist to automatically generate fixes for buggy code. However, due to the large combinatorial space of possible solutions for a particular bug, there are not many tools and datasets available to evaluate generated code effectively. In this work, we introduce FixEval, a benchmark comprising buggy code submissions to competitive programming problems and their respective fixes. We introduce a rich test suite to evaluate and assess the correctness of model-generated program fixes. We consider two Transformer language models pretrained on programming languages as our baselines, and compare them using match-based and execution-based evaluation metrics. Our experiments show that match-based metrics do not reflect model-generated program fixes accurately, while execution-based methods evaluate programs through all cases and scenarios specifically designed for that solution. Therefore, we believe FixEval provides a step towards real-world automatic bug fixing and model-generated code evaluation.
Attention Mechanism based Cognition-level Scene Understanding
Apr 19, 2022
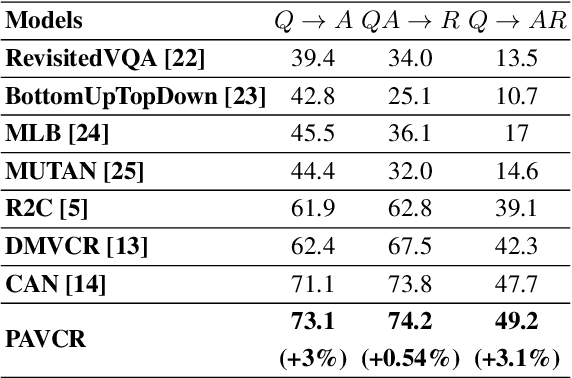
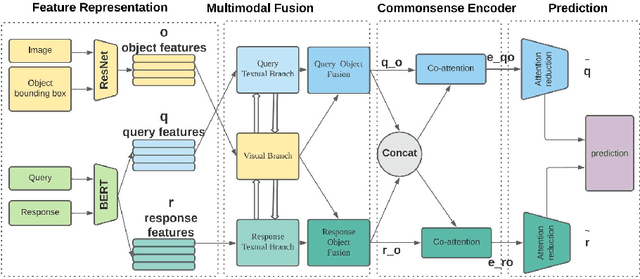

Given a question-image input, the Visual Commonsense Reasoning (VCR) model can predict an answer with the corresponding rationale, which requires inference ability from the real world. The VCR task, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge, is a cognition-level scene understanding task. The VCR task has aroused researchers' interest due to its wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and losing information in long sequences. In this paper, we propose a parallel attention-based cognitive VCR network PAVCR, which fuses visual-textual information efficiently and encodes semantic information in parallel to enable the model to capture rich information for cognition-level inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning.